谷歌在 5 月 19 日的 I/O 2026 大会上正式推出了 Gemini Omni Flash — 这是首个具有真正多模态输入的原生视频生成模型。我们对官方发布、模型能力、早期行业测试以及这对创作者意味着什么进行了全面拆解。
1. 官方发布:发布了什么
北京时间 2026 年 5 月 20 日凌晨,谷歌 I/O 2026 大会正式拉开帷幕。在众多眼花缭乱的 AI 发布中,Gemini Omni Flash 脱颖而出 — 这是 Gemini 家族中一款全新的视频模型,而且这一次它不是概念演示。它是一个真实、在线的产品发布,用户可以通过 Gemini 应用程序、Google Flow、YouTube Shorts 和 YouTube Create 进行访问。
谷歌的定位非常明确:“我们迈向能够从任何内容创建任何内容模型的第一步 — 从视频开始。” 您可以使用文本、图像、音频甚至现有的视频剪辑作为输入,该模型将生成具有同步音频输出的高分辨率视频。
🔥 四大官方亮点
根据谷歌在发布会上分享的内容,以下是 Omni 真正脱颖而出的几个方面:
🧠 物理理解 × 世界知识:从写实主义到有意义的叙事
Omni 将更强的物理理解与 Gemini 在历史、生物和文化方面的现有知识库相结合。动作会产生结果,环境会对事件做出反应,叙事逻辑自然展开。这不仅仅是“帧生成” — 而是模拟一个会思考的视频世界。
🎭 角色一致性:一次定义,随处使用
一次定义角色,然后将其拖入任何场景。无论在什么地点、光照条件和动作下,角色都能保持一致。对于系列内容创作者来说,这可能会彻底改变游戏规则。
🎨 参考驱动的输入:用图片或语言定义风格
输入参考图像或视频片段作为风格输入,或者用自然语言描述您想要的视觉运动和效果。您甚至可以使用自己的视频作为输入,让 Omni 重新解释运动和场景。
🪄 实时环境转换
通过对话改变环境、添加新对象、创造完全出乎意料的内容。
发布时间线
| 日期 | 里程碑 |
|---|---|
| 📅 2026 年 5 月 19 日 | 谷歌 I/O 2026 大会正式揭幕。Gemini Omni Flash 被宣布为 Omni 家族中的首个视频模型 |
| 🚀 发布当日 | Google AI Plus、Pro 和 Ultra 订阅用户可通过 Gemini App 和 Flow 进行访问(按层级和地区逐步推广) |
| 🔜 即将到来 | 开发者/企业 API 访问 — 模型 ID、定价、配额和内容政策细节预计将在未来几周公布 |
💡 FastMoroAI 观点
与谷歌过去“只展示视频但从不发货”的作风不同,Omni Flash 立即向订阅用户开放。这是一个强烈的信号 — 谷歌正在加速 AI 视频赛道的竞争。
2. Gemini Omni Flash 模型卡:能力与局限
官方模型卡 (deepmind.google) 提供了相对详细的技术规格。以下是核心重点:
📊 模型规格一览
| 类别 | 详情 |
|---|---|
| 架构 | Transformer (原生多模态) |
| 输出 | 高分辨率视频 + 音频 |
| 输入类型 | 文本 / 图像 / 音频 / 视频 (混合输入) |
| 核心工作流 | 对话式多轮视频编辑 |
| 世界知识集成 | 历史 / 科学 / 文化 / 物理 / 叙事 |
| 谷歌标记的改进领域 | 多轮编辑一致性、复杂运动表现 — 谷歌在模型卡中明确指出了这些,展示了工程上的透明度 |
✨ 五大核心能力
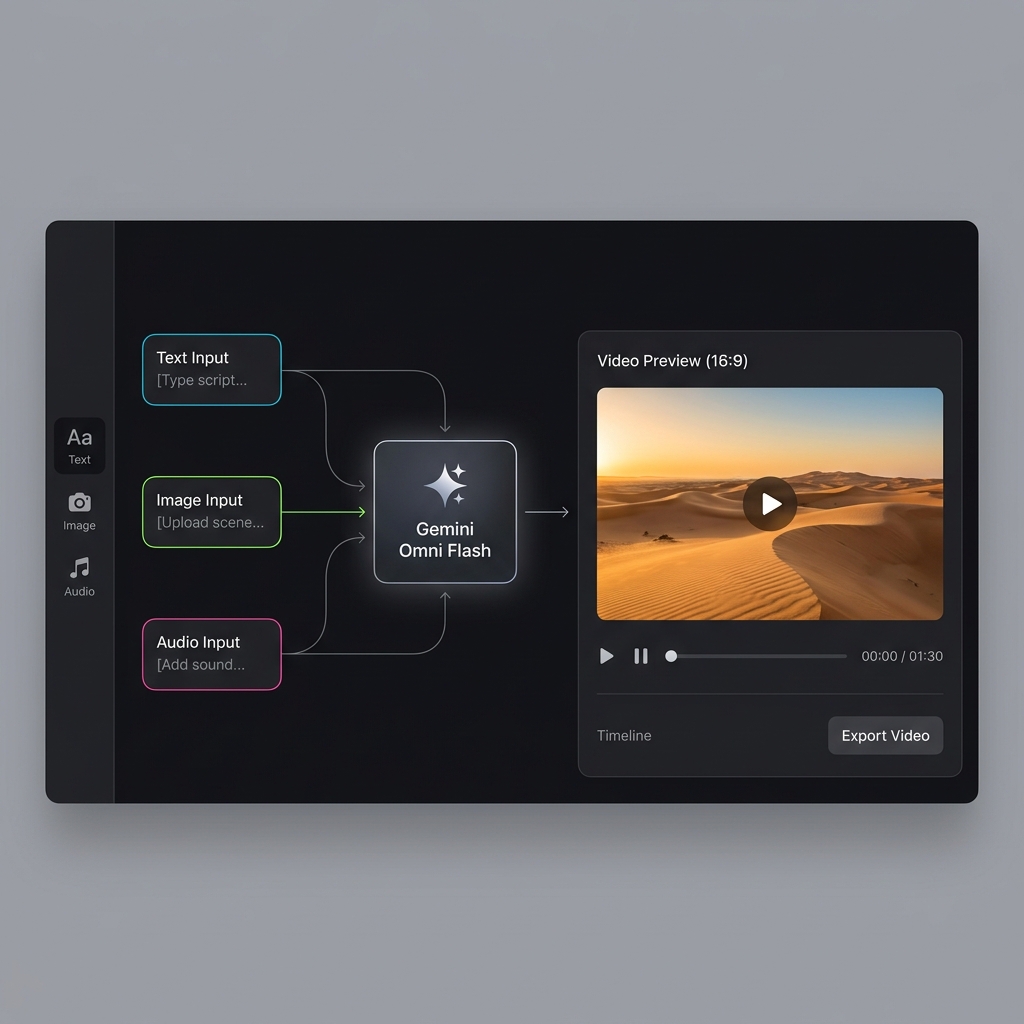
🎬 混合输入创作
这不仅仅是文生视频。草图、音频、视频剪辑、参考图像 — 所有这些都可以协同驱动创作。这是 Omni 与其他模型最大的差异化特征。
💬 对话式编辑
生成基础场景后,用自然语言微调摄像机角度、风格或运动 — 无需从头开始。对话式编辑是核心工作流,而非附加功能。
🧠 世界知识驱动
利用 Gemini 的知识库进行历史重建、科学可视化、文化叙事和其他复杂主题的创作。这是目前任何纯视频生成模型都不具备的优势。
🎭 跨场景角色一致性
官方声称:只需定义一次角色,将其放入任何场景,他们就能保持一致。地点、光线和运动的变化不会破坏角色的一致性。这对系列视频内容非常关键。
🪄 实时环境转换与参考输入
上传参考图片或剪辑,Omni 即可应用其风格、运动或效果。或者只需通过对话改变整个场景环境并添加对象。
💡 模型卡显示谷歌在这方面表现得很坦诚 — 他们明确将多轮编辑一致性和复杂运动列为仍在优化的领域。对于创作者来说,了解模型的真实边界比盲信“无所不能”的营销更有价值。
3. Gemini Omni 对比 Veo:替代还是共存?
在谷歌宣布新视频模型的那一刻,所有人都会问第一个问题:“Veo 凉了吗?” 简而言之:并没有。 它们是定位截然不同的独立模型系列。
“Gemini Omni 是创意助手,Veo 是电影级生成引擎。一个专为交互式工作流打造,另一个则专注于高保真视觉质量。”
正面对比
| 维度 | Gemini Omni Flash | Veo 系列 |
|---|---|---|
| 定位 | 具有多模态混合输入的原生创意模型,专注于视频创作与编辑 | 谷歌的专属视频模型,专注于电影级质量的生成(含音频) |
| 主要工作流 | 具有多轮编辑的对话式视频创作 | 谷歌生态系统内基于提示词驱动的生成 |
| 输入重点 | 文本 + 图像 + 音频 + 视频参考(混合) | 文本和图像(因平台而异) |
| 差异化 | 多轮编辑、参考资产、世界知识、混合输入合成 | 电影级生成质量、原生音频、现有的 API/产品集成 |
| API 状态 | 即将到来(已宣布) | 开发者接口已有文档记录并可用 |
⚠️ 实用建议:现在不要急于倒向任何一边。如果您有 Gemini 订阅,可以尝试使用 Omni。如果您需要稳定的 API 管道,Veo 仍然是更成熟的选择。
4. 提示词工程指南:如何最大化利用 Omni
谷歌的官方提示词指南 (deepmind.google) 提供了结构化的建议。基于我们的分析和优化,这里有七个基本元素 — 漏掉任何一个,效果都可能明显打折扣。
七大元素框架
| # | 元素 | 描述 |
|---|---|---|
| 🖼️ 1 | 定义画面 (Define the Frame) | 全景、特写、过肩、微距、固定镜头 — 首先确立您的视觉语言 |
| 🎥 2 | 相机行为 (Camera Behavior) | 推镜头、环绕、仰角、缩放、手持 — 描述相机如何运动 |
| 🌈 3 | 视觉语言 (Visual Language) | 风格 + 光照 + 环境的协同作用,例如“温暖台灯下的写实产品广告” |
| 🏃 4 | 定义运动 (Define Motion) | 谁在运动?什么必须保持静止?明确指出变化与不变化的部分 |
| 🔡 5 | 文字处理 (Text Handling) | 指定确切的文本内容、位置,以及是否允许出现其他文本 |
| 🔊 6 | 音频处理 (Audio Handling) | 环境音、音乐、特效音、卡点或静音 — 明确拼写出来 |
| ✏️ 7 | 精确编辑 (Precision Editing) | 务必同时澄清“需要改变什么”和“需要保留什么” — 这才是对话式编辑的实际运作方式 |
💡 核心技巧:编辑提示词需要同时指定改变了什么以及保留了什么。同一个角色、同一个房间、同一个序列 — 但更换对象/角度/风格。明确列出要保留的元素,对话式编辑才会真正变得好用。
5. 早期实测观察:来自 PixVerse 的三项评估
⚠️ 重要免责声明:以下三个测试场景和结果来自 5 月 20 日发布的 PixVerse 博客评测。PixVerse 是 AI 视频生成领域的竞争平台,其评估视角可能带有主观偏见。FastMoroAI 尚未进行独立测试。我们在此原样呈现原始评测结果,并附带我们自己的分析。
PixVerse 设计了三个具有代表性的测试场景,涵盖电影叙事、知识可视化以及社交短视频。以下是具体的测试结果:
🎬 测试 1:电影级相机与连续镜头一致性
目标:评估相机运动、主体一致性、光照对比、物体稳定性和场景连续性等综合表现。
Create a 10-second 16:9 cinematic video in one continuous shot.
A young product designer sits at a small desk beside a rainy window,
opens a sketchbook, and a compact silver drone design rises from the page
as a realistic hologram. The camera starts as a close-up on the pencil tip,
slowly pulls back to a medium shot, then gently orbits left as the hologram
rotates above the page. Warm desk lamp light, cool blue rain outside,
shallow depth of field, realistic hand motion, no subtitles, no logos,
natural room ambience only.🎯 测试重点:拉镜头 / 主体一致性 / 冷暖光对比 / 物体稳定性 / 叙事连贯性
PixVerse 测试报告:
| 维度 | 结果 |
|---|---|
| ✅ 优势 | 氛围感极强 — 冷暖光对比、手部动作、浅景深都表现出色。情感表达连贯。 |
| ⚠️ 反馈 | 无人机全息图的“呈现瞬间”没有完全达到预期效果 |
🎙️ FastMoroAI 分析:这种电影叙事场景直接切中了 Omni 的核心优势。官方强调的“物理理解”和“世界知识”在这里得到了充分体现。连贯的冷暖色调光照和流畅的摄像机运动表明 Omni 底层的物理模拟已经达到了相当高的水平。
🧪 测试 2:世界知识科普 — 经典计算与量子计算
目标:测试模型将抽象概念转化为视觉逻辑的能力,并验证负面约束(“无人类手部”)是否得到遵守。
Create a 10-second educational explainer video about the difference between
classical computing and quantum computing. Use a tactile stop-motion paper-craft
style on a dark tabletop. Show a single classical bit as a small paper switch
flipping between 0 and 1, then show a qubit as a glowing paper coin spinning
with both states implied before measurement. Use clear visual metaphors,
accurate motion, soft overhead light, no human hands, no voiceover,
no on-screen text except the exact labels "bit" and "qubit" placed beside the objects.🎯 测试重点:概念可视化 / 受限文本管理 / 负面约束遵守
PixVerse 测试报告:
| 维度 | 结果 |
|---|---|
| ✅ 优势 | 概念上最成功的测试。“bit”和“qubit”标签清晰可读。纸艺风格契合度高。视觉隐喻清晰。 |
| ⚠️ 反馈 | 提示词中指定了“无人类手部”,但输出中依然出现了手(负面约束未完全遵守) |
🎙️ FastMoroAI 分析:一个值得注意的细节 — PixVerse 的报告明确指出 “bit”和“qubit”标签是清晰可读的。 这意味着 Omni 的文本渲染并非“完全不可用”。对于文本量有限的概念可视化场景,其表现至少达到了可用水平。负面约束的准确性确实值得关注,但这类问题在刚发布的模型中相当普遍。
🖋️ 测试 3:节奏感社交短视频
目标:测试排版精度、卡点控制、宽屏布局稳定性以及对确切文本约束的遵守。
Create a 9-second horizontal 16:9 social video for an AI video creation tip.
A clean black studio background with a floating glass timeline interface
stretched across the frame. Each word appears one at a time in perfect rhythm
with soft electronic clicks: "prompt", "reference", "motion", "lighting", "sound".
Each word has a different tasteful animation style, but the timeline and camera
stay stable. End with all five words arranged as a neat widescreen checklist.
High contrast, crisp typography, no extra words, no brand names.🎯 测试重点:排版精度 / 节奏控制 / 宽屏布局 / 文本约束遵守
PixVerse 测试报告:
| 维度 | 结果 |
|---|---|
| ✅ 优势 | 玻璃时间线界面和宽屏构图在视觉上非常震撼 |
| ⚠️ 反馈 | 一些精确的单词出现了扭曲或文字碎片伪影(注:这是首发当天的初代测试结果) |
🎙️ FastMoroAI 分析:这是三个测试中最极端的一个约束测试 — 五个独立的单词随着精确的卡点依次出现,且容错率为零。对于任何刚发布的视频模型来说,这都属于压力测试的范畴。鉴于测试 2 已经证明 Omni 能够很好地处理有限的文本,我们建议等模型更加稳定后再去评判它在这一维度上的上限。
6. 综合评估:已知信息与待验证领域
结合官方公告、模型卡以及有限的早期第三方测试,我们得出以下基于证据的评估:
✅ Omni 已确认的优势(来源:官方公告与模型卡)
- 物理理解 × 语义智能:非简单的像素预测 — 模型理解因果关系、环境交互和叙事逻辑
- 跨场景角色一致性:一次定义,随处使用 — 这是目前大多数视频模型所不具备的能力
- 实时环境转换:通过对话改变场景、添加对象、重构视觉元素
- 参考驱动输入:图像、视频和音频均可作为风格和运动参考源
- 世界知识集成:Gemini 跨历史、科学和文化的知识库直接为内容创作赋能
- 对话式迭代编辑:多轮编辑能够保留上下文,实现渐进式微调
🔍 待进一步验证的领域(来源:早期第三方测试 — 非最终结论)
- 多轮编辑后的主体一致性:谷歌模型卡直白地将此列为积极优化的领域
- 对复杂运动轨迹的精确控制:同样被谷歌列为待改进领域
- 极端约束下的表现:模型在严格的负面约束或极高排版需求下的表现仍需独立的第三方验证
💡 核心结语:Omni 的核心竞争优势并不在于“在每一个维度上都表现完美”,而是它带来了其他任何视频生成模型都不具备的能力:物理理解、角色一致性以及世界知识驱动的创作。 这些是真正的差异化赛道,而非对现有范式的微小改良。
⚠️ 关于文本渲染的说明:尽管一些早期的第三方评测对文本渲染提出了担忧,但在同一评估中,“bit”/“qubit”标签也被认为是清晰可读的。谷歌并未在模型卡中将文本渲染列为已知限制。我们认为现在下结论还为时过早 — 需要更多独立的测试。
7. 你现在应该加入吗?创作者建议
简而言之:如果您有访问权限,是的 — 现在就去尝试。 但不要把您的全部制作管线都押在一个尚未上线的 API 上。
✅ 值得现在尝试的场景
- 您已经拥有 Google AI Plus / Pro / Ultra 订阅
- 您想测试对话式视频编辑工作流
- 混合参考创作(图像 + 音频 + 视频输入)
- 科普内容、社交视频、概念可视化
- 创作者实验和迭代优化
⚠️ 值得继续观望的场景
- 围绕 API 构建生产工作流(API 尚未提供)
- 需要稳定的配额、价格或具体的区域政策细节
- 对多轮编辑一致性有极高要求的场景
- 对模型行为的 SLA(服务等级协议)有严格要求的商业用例
“最佳策略是多模型并行工作流:在谷歌生态系统内使用 Gemini Omni 进行实验;同时使用其他平台(如 FastMoroAI)获取更易用的视频生成和稳定的 API 管道。在不同模型之间运行相同的创意简报并对比结果 — 这才是找到最适合您工作流的方法。”
⚡ 想要用 FastMoroAI 体验 AI 视频生成?
集成 GPT Image 2、Image to Live 以及多种主流 AI 视频/图像模型 — 支持图文混合创作工作流,开箱即用。
8. 常见问题 (FAQ)
Q: Gemini Omni Flash 现在可用了吗?
A: 是的 — 2026 年 5 月 19 日正式发布。Google AI Plus、Pro 和 Ultra 订阅用户可以通过 Gemini 应用程序和 Google Flow 进行访问,按层级和地区逐步推广。
Q: Gemini Omni 和 Veo 是同一个模型吗?
A: 不是。它们是独立的模型系列 — Omni 专注于对话式多模态创作,Veo 专注于电影级画质的视频生成。可以把一个看作是“创意助手”,另一个看作是“电影引擎”。
Q: 我可以通过对话编辑视频吗?
A: 这正是 Omni 的核心功能。在生成基础场景后,您可以使用自然语言指令调整相机角度、风格、对象和动作 — 模型会在保留原内容的同时进行局部修改。
Q: 开发者 API 什么时候可用?
A: 谷歌已宣布即将推出开发者/企业级 API,但具体的模型 ID、定价、配额和内容政策细节尚未公布。预计在未来几周会有更多信息披露 — 敬请关注官方渠道。
Q: Omni 最大的局限性是什么?
A: 根据谷歌官方模型卡,多轮编辑后的主体一致性以及复杂的运动轨迹是仍在优化的领域。由于目前的独立实测数据非常有限,我们建议持续关注官方更新,且已有的公开信息不宜作为最终评判依据。
Q: 它支持音频吗?
A: 支持。您可以输入音频文件作为参考,且输出的视频会包含同步的音轨。
参考资料
- 谷歌官方公告:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni/ - Gemini Omni Flash 模型卡:
deepmind.google/models/model-cards/gemini-omni-flash/ - 官方提示词指南:
deepmind.google/models/gemini-omni/prompt-guide/ - 来源参考:PixVerse Blog — Gemini Omni Flash Official Release and Prompt Guide
由 FastMoroAI 发布于 2026 年 5 月 21 日
内容综合自谷歌官方发布会、模型卡文档以及公开的第三方评测。PixVerse 测试结果仅供参考,不代表 FastMoroAI 的独立测试结论。如有更新,请以谷歌官方公告为准。